How to run an LLM on your desktop Linux?
This is old. Go away, use some up-to-date tooling like this: Offline Coding Agent with VSCode, Cline, and Ollama
My friend, Pöri just came over being happy about how he made Llama cpp run on his machine under an hour, so I had to try my own. He used this guide for Mac - its surprisingly easy I believe even for a semi-tech person.
I have a Thinkpad 1 Extreme Gen 1 with 32GB RAM with 4GB video memory, and it's running reasonably acceptable speed even without GPU support! I am running PopOS 22.04 LTS.
Also, Meta's Llama2 model has permissive licence, and can be used commercially!
Install and Compile
#!/bin/bash
# Following linux tools are needed:
sudo apt install make cmake build-essentials
# For GPU support, you'll need to install CUDA toolkit
sudo apt install nvidia-cuda-toolkit
# Use dev!
mkdir -p ~/dev
cd ~/dev
# Checkout the repo
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
# Compile for CPU:
makeTo get the CUDA compile to work, I had to modify the Makefile in order to not fail:
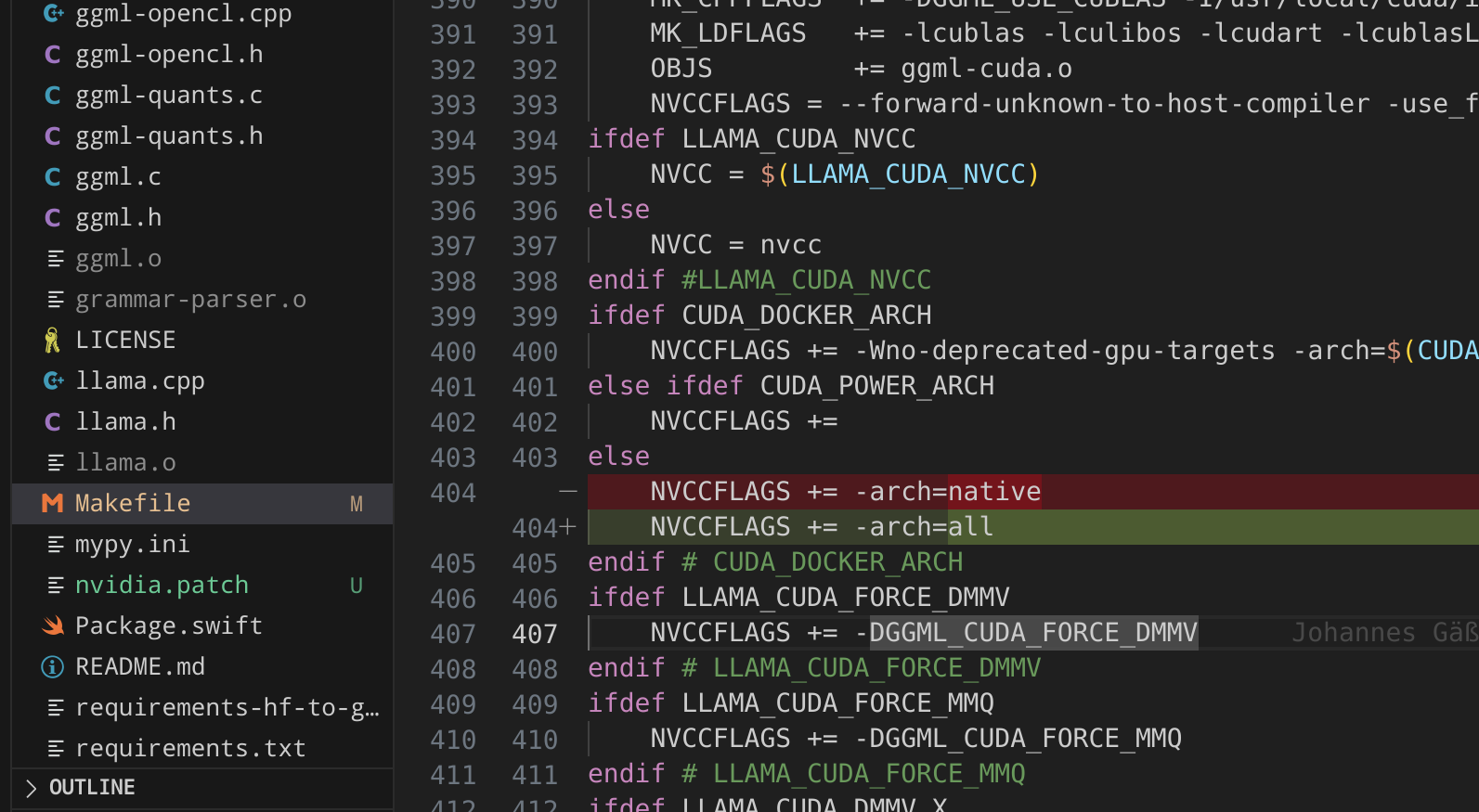
This made the compilation work:
# Compile for CUDA GPU (NVIDIA)
make LLAMA_CUBLAS=1The Model
Download the files from hugging-face: e.g.
export MODEL=llama-2-13b-chat.ggmlv3.q4_0.bin
curl -L \
"https://huggingface.co/TheBloke/Llama-2-13B-chat-GGML/resolve/main/${MODEL}" \
-o models/${MODEL}Convert the bin model to a gguf model:
python3 convert-llama-ggml-to-gguf.py \
--input models/llama-2-13b-chat.ggmlv3.q4_0.bin \
--output models/llama-2-13b-chat.ggmlv3.q4_0.ggufOther versions
This is a 7GB model - and this has an acceptable speed. I also tried to run the llama-2-70b.ggmlv3.q8_0 model too, convert it to gguf but it had 0.02 token/sec speed, so that's not exactly usable.
Running
I also wrote a llama runner for my params :
#!/bin/bash
SCRIPT_PATH=~/dev/llama.cpp/
MODEL_PATH=~/dev/models/llama-2-13b-chat.ggmlv3.q4_0.gguf
# CPU
if [ "$1" = "cpu" ]; then
echo "Running on CPU"
$SCRIPT_PATH/main -m $MODEL_PATH \
--color \
--ctx_size 2048 \
-n -1 \
-ins -b 256 \
--top_k 10000 \
--temp 0.2 \
--repeat_penalty 1.1 \
-t 8
else
echo "Running on GPU"
### NGL flag: Depending on the vram size, for me, ngl 15 swallows about 3gb of vram with the 7GB model
$SCRIPT_PATH/main -m $MODEL_PATH \
--color \
-ngl 3 \
--ctx_size 2048 \
-n -1 \
-ins -b 256 \
--top_k 10000 \
--temp 0.2 \
--repeat_penalty 1.1 \
-t 8
fiAfter making it runnable with chmod +x llama
linked it to ln -s ~/dev/llama.cpp/llama /usr/bin
It does not know good pizza recepise, but other than that, it runs really nicely.
In case of an apocalypse, now you can still talk to a chat-bot if you saved a 7GB file on your drive, that can code fairly decently!
The future is now.
linux machine-learning ChatGPT llama